

In our day-to-day practice as TCP relationship therapists (aka TCP connection troubleshooters) for cloud services, applications and networks we have learned that putting a TCP session data solution into action is experienced as a challenging, complex task. Most of the time the concerns are related to not having visibility on the complete application chain.
Fortunately, the low hanging fruit when starting with end-to-end performance monitoring is about rationalizing and prioritizing user complaints.
This is because in today’s hybrid, software defined networks the by far largest grey area is the combination of security zones and the different types of network/SD-WAN connections; including the local internet ones and the security layers on top of that.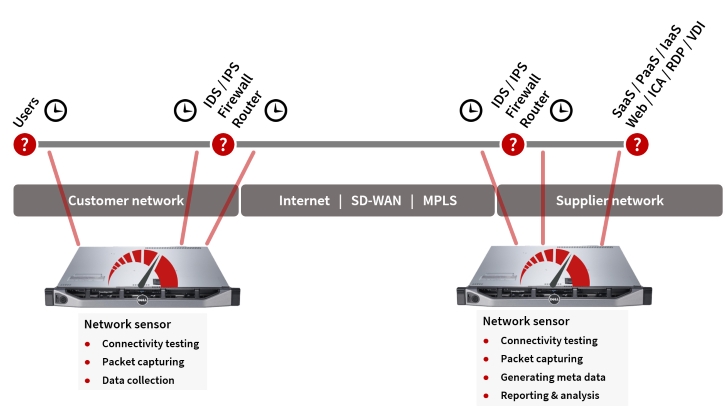 As it happens, this large grey area is the most important TCP session data source for analyzing the behavior of cloud services and applications as experienced by the users. Moreover, identifying the appropriate data collection points is easy since the amount of network devices involved in a WAN connection is very limited.
As it happens, this large grey area is the most important TCP session data source for analyzing the behavior of cloud services and applications as experienced by the users. Moreover, identifying the appropriate data collection points is easy since the amount of network devices involved in a WAN connection is very limited.
This allows us to simplify and standardize the solution deployment with 3 easy steps:
- Setting up the TCP data collection part for the front-end
- Modelling all incoming TCP session data
- Validate the configuration and the initial results
Once these steps are completed, your teams have a clear understanding about the user experience for each of the cloud services and applications being monitored. This includes an understanding about which of the IT domains is causing the delays:
- Is it the end-user device, the network, a cloud service or an application?
- And if a combination of these, to what extend each and where to start improving things?
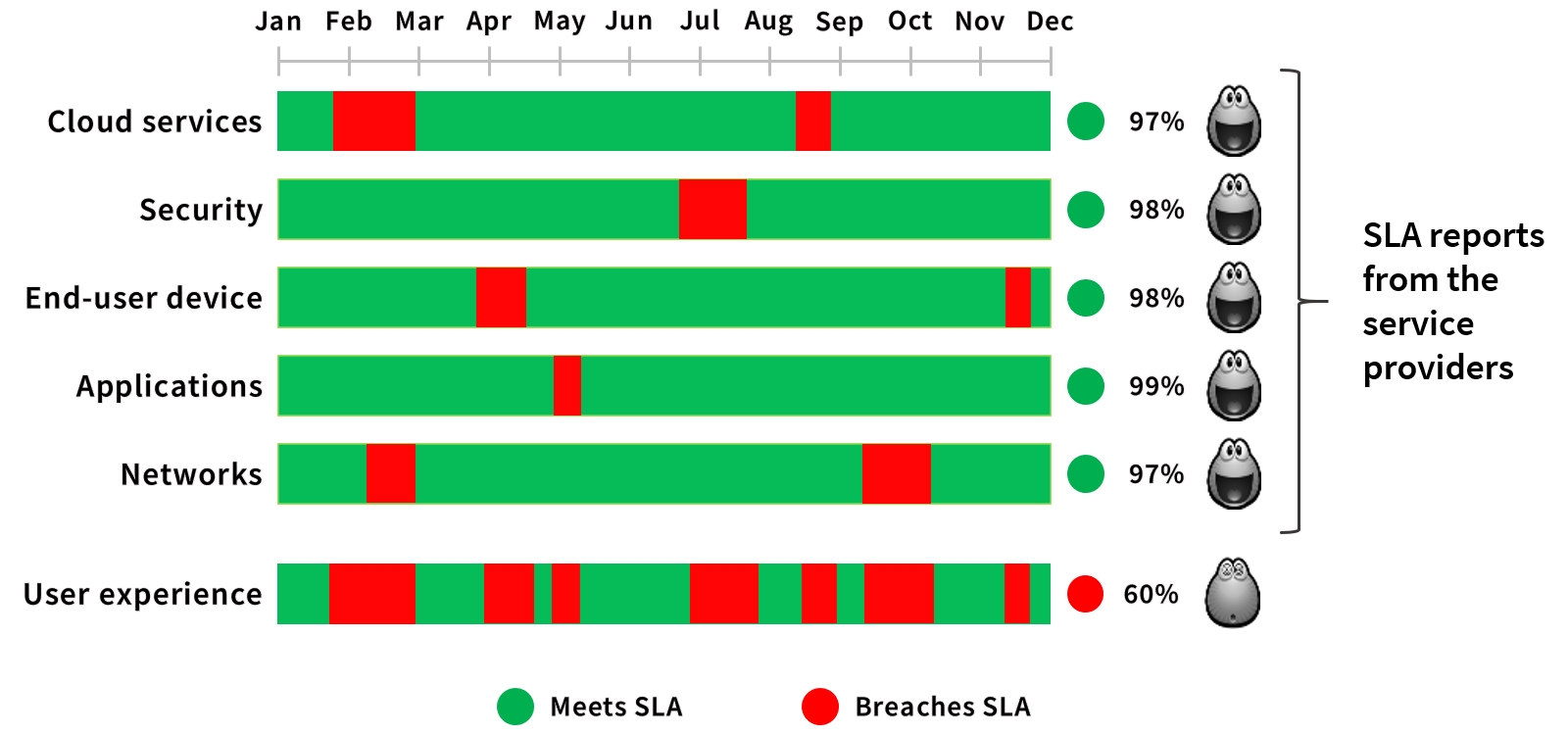
Moreover these teams will also benefit from having a consistent troubleshooting workflow with a quick and predictable outcome when analyzing performance issues.
Combined, this helps your IT organization in preventing time-consuming conversations about which party (or parties!) to involve when improvements are required like yesterday.
step 1 – Setting up the TCP data collection part
Since this is a TCP session oriented setup we need access to packets through port mirroring (also known as span ports) and/or taps .
Port mirroring is something that is configured on a network device and is about copying packets to a specific port on that network device.
A tap is about connecting a device in-line between 2 network devices. This device then copies all incoming data to one of the 2 outgoing ports.
As a rule of thumb we recommend the following:
- Taps are used for collecting TCP session data between 2 network devices like for example routers, switches, load balancers and firewalls to prevent additional delays.
- Port-spanning/port-mirroring is used for data collection about the hosts connected to a network device and hosts running on a hypervisor.
A typical use case for taps is the need for a detailed performance breakdown of an application chain; including analyzing the performance impact of network devices like load balancers, firewalls and IDS/IPS systems.
Typical use cases for port mirroring are monitoring the user experience in offices as well as monitoring the performance between to or more virtual machines.
More information on the pro’s and con’s about taps and port-spanning/port-mirroring is found here. This post includes a detailed, comprehensive description of a rock-solid packet capture foundation.
Once this stage is completed, the monitoring solution is connected and the data collection starts; moving forward to modelling the incoming TCP session data.
step 2 – Modelling the incoming TCP session data
Modelling this session data is all about translating the raw data into easy-to-understand dashboards and reports. Assigning data to groups representing applications, locations and hosts already covers 80% of the configuration work for improving problem resolution times. This is because:
- Each location group represents a certain group of end-user devices.
- Each host group represents a certain group of systems related to a security zone in a data center.
- Each application group represents a certain group of systems and/or cloud services belonging to a certain application chain.
These 3 group types are the key elements in an improved workflow around analyzing and troubleshooting performance issues.
The remaining 20% is related to making a jump start on the plan-do-check-act cycle for embedding this improved troubleshooting workflow in your current processes.
We recommend starting with 3 reports as common ground for making his happen:
- A daily report covering day- and night-time (i.e. from 7 AM to 7 PM and from 7 PM to 7 AM).
- A weekly report covering from Monday to Monday; both at 7 AM.
- A monthly report covering 1st day of the month to 1st day of the month; again, both at 7 AM.
The recommended content for each of the reports includes (1) – a high level summary about the health of the most important, business critical applications, (2) – a break down into the performance levels and (3) – the details for starting the analysis and troubleshooting process.
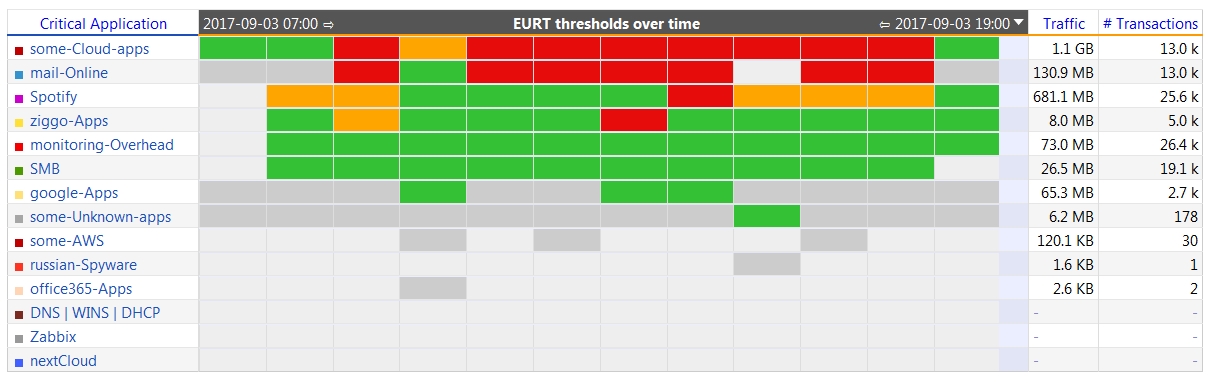
An example of a high level summary
Click here to get your copy of the report examples; including a one-pager guiding you in the interpretation. Please note that depending on your browser and its settings this form opens a new window.
The combination of 3 group types and 3 reports allow your teams to make significant improvements on reducing problem resolution times.
step 3 – Validate the configuration and the initial results
Once the TCP session data is modeled, we run a quick health-check of the monitoring system to make sure everything is working as expected:
- The utilization of the data capture interfaces.
- The amount of packet drops (if any).
- The CPU, memory and disk utilization of the monitoring solution.
We strongly recommend an end-to-end monitoring solution that gives you visibility on short- and long term metrics on each of these 3 topics. Especially short term is important since more often than not, micro bursts of data can be the root-cause for a monitoring solution that is suffering.
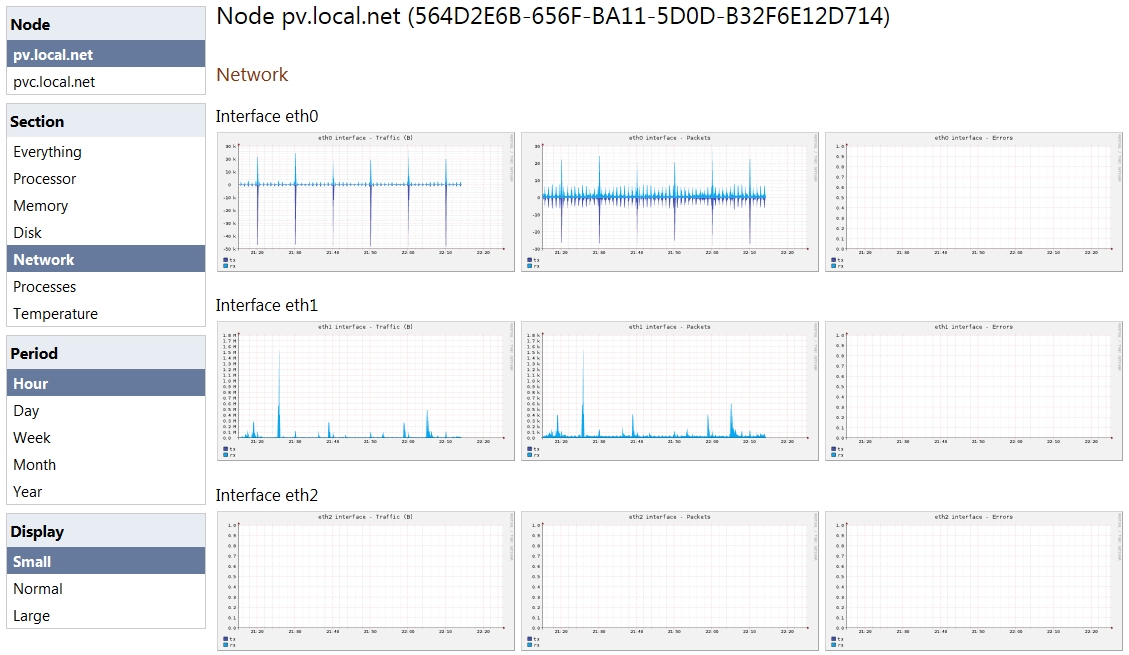
A quick health-check of the monitoring system
Where to go from here
This completes our best practice about a jump start on end-to-end performance monitoring. The approach outlined in the previous 3 steps is the core of our offerings called Health-check and Visibility-as-a-Service.
Use this form to get your copy of the report examples and a one-pager guiding you in the interpretation.
Or even better: try it yourself; it is free, fun and above all educational! Click here to get started.
If you need more technical details on how we do this then we recommend having a look at our case study about a Health-check on Citrix/SAP.
![]()