

More often then not, DevOps and ITOM organizations are requiring role based dashboards when deploying Network- and Application Performance Monitoring (NPM/APM) solutions. Meaning for “security and compliance reasons”, the content on each of these dashboards can only be viewed by someone with with the appropriate access rights.
However, once deployed, I have noticed that these type of dashboards are rarely effective and efficient in improving the overall performance and availability of a given hybrid IT environment.
Taking one step back… the purpose of an NPM/APM solution is to improve the performance and availability of cloud services, applications and its underlying hybrid infrastructure. This is (should be?) the common ground across the teams of any IT organization; regardless if the teams are labelled with ITOM or DevOps.
This is because all teams really do have a certain influence on the performance and availability (figure 1). It doesn’t really matter if the role is related to management processes or “just” about technology. Therefor, I always found it difficult to understand how such a common ground can be a risk that requires hiding information as a way of mitigation.
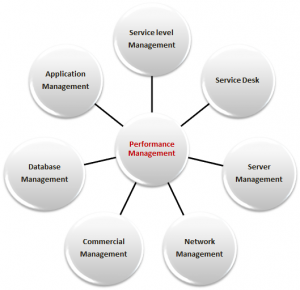
figure 1 – Collaboration between ITOM and DevOps teams
Learning to work with a NPM/APM type of solution based on this type of role based dashboards give you results very similar to single-loop learning (Argyris & Schön, 1991). As shown in figure 2, single-loop learning means that the people and teams responsible for a specific technology learn to use the solution by comparing pre-defined, expected results (i.e. the “What We Do”) with the actual results (i.e. the “What We Get”). Based on these results, changes are initiated to fix problems of a specific IT area.
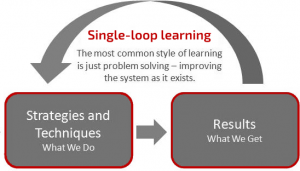
figure 2 – Single-loop learning
This means that the skills learned with the use of a performance management solution will indeed result in improvements for a specific area belonging to a specific role. However, based on my experience, specific performance improvements in one area often affects the performance in another area. Which then results in countless improvements loops.
What is missing is the beliefs, policies, assumptions, etc. that lead to the initial, expected results. What is also missing is that nobody is reviewing the pre-defined and actual results as a whole and decide on the required changes in one or more IT area’s.
Make it work better by learning from each other
These missing topics come to the table seamlessly when everybody has access to all dashboards. Because while colleagues may not be considered non-subject matter experts in a certain field, they may have just enough knowledge to come up with some out-of-the-box ideas about potential improvements.
This forces the ones that are considered subject matter experts to question the relevancy of their beliefs and assumptions that drives the initial, expected results. As a result the teams learn to (re-)evaluate the expected and actual results against assumptions and beliefs coming from different area’s of expertise.
This approach is known as double-loop learning (Argyris & Schön, 1991). As shown in figure 3 double-loop learning does not only look at the existing methodology, but also challenge the things that lead to this methodology (i.e. the Why We Do What We Do). Therefore, this approach is complementary to single-loop learning as described previously.
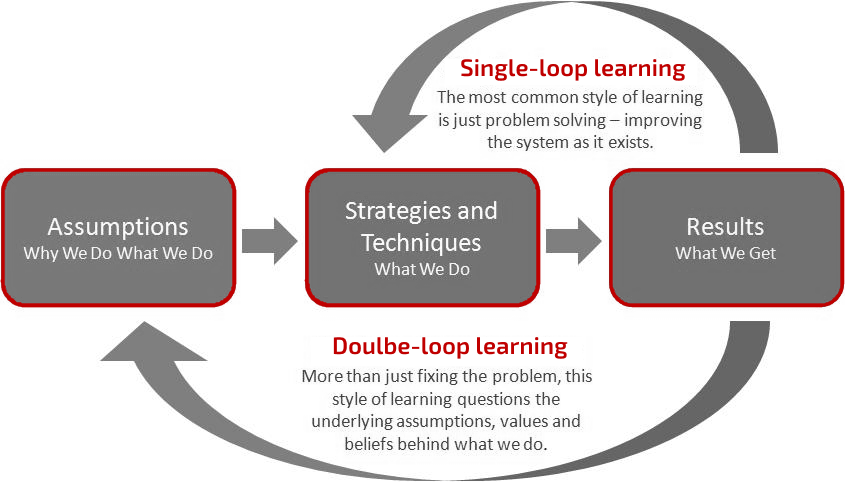
figure 3 – Double-loop learning
Double-loop learning has proven to be most successful in organizations with learning environments. Meaning to a certain extend, the teams are allowed experiment with their theories of action. This allows them to question their underlying views and assumptions. Moreover hypotheses brought to the table by subject matter experts are challenged by the rest of the teams.
The end result is a far better ROI (Return On Investment) due to an increased effectiveness in the improvements as well as a better acceptance of failures and mistakes.!
References
Yatin Paware (30-sept-2016). Effective Agile performance management with double loop learning.
Argyris, C., & Schön, D. (1991, may 1). Double-loop learning. Retrieved from Wikipedia: https://pds8.egloos.com/pds/200805/20/87/chris_argyris_learning.pdf