

 In today’s cloud and hybrid era, performing and responsive cloud services and applications are one of the main concerns for any organization. The foundation for these are healthy relationships!
In today’s cloud and hybrid era, performing and responsive cloud services and applications are one of the main concerns for any organization. The foundation for these are healthy relationships!
This is the 4rd post in a series of 5 about the core of our best practices as TCP relation therapists for cloud services, applications and networks. These 5 posts are available in one convenient PDF; click here to get your copy.
During the previous post, you learned how to identify and analyze the not-so healthy endings of a relationship and how this impacts the user experience. The case study about a Health-check on the Dutch “Daisylezer”-app and the underlying streaming media platform shows clearly how such behavior impacts an app and its user experience!
In this post you will learn how to discover the low hanging fruit for getting healthy relationships (again) and improve the user experience in the process.
As explained earlier, persistent not-so healthy starts and endings of a relationship will certainly impact the user experience; especially if there are reasons to believe that hosts are overloaded and messages are delayed or dropped. A persistent increase on the amount of 0-Win-events and duplicate acknowledgements are typically good indicators for such not-so health behavior!
6 easy steps to find the root-cause
Finding the root-cause can be challenging and time consuming. The next 6 steps enable you to speed-up this process; including some actionable pointers to low hanging fruit when looking for improvements.
- Start with ruling out an overloaded client- or server-side by taking a look at the amount of 0-Win events.
If these events are coming in rapidly, you may want to involve the respective desktop or system administrator(s) and have a look at the workload on these hosts. - If the amount of 0-Win events is close to zero (as it should be!), then most likely, the problem is somewhere on the network path between the client- and server-side. If both are within the same subnet, it should be fairly easy to figure out where the delays and/or drops are coming from. A quick look at the MAC-tables from the connected network devices should tell you which devices and interfaces are involved.
- If the client- and server-side are not within the same subnet, it means one or more routers (or something similar) are involved. Start with finding the intermediate subnets, devices and interfaces by looking at the MAC-addresses and routing tables of the designated gateway on the client- and server-side. This should tell you what other routers and interfaces are actively involved in sending and receiving their messages.
- If it turns out that both MAC-addresses are pointing to the same routing device, then most likely that routing device has too much things to do besides routing messages. For example because the device is actually a firewall with (too?) many policies. Perhaps it is a load-balancer running CPU intensive tasks like being an IPS, doing SSL offloading and data compression. Now is probably a good time to involve the system administrator of these devices.
- However, if both MAC-addresses are pointing to different routing devices, then most likely one or more WAN connections are involved. If redundant, check the load-sharing algorithm on the routers. Modern IP route switches support message based load-sharing. While this is a very effective way of doing load sharing, it may result in some unexpected site effects. Such asymmetric network paths may require additional processing time on the hosts as the order by which messages are received might be changed.
- Once you have an understanding on the devices and interfaces between the client- and server-side, start looking at things like CPU and memory utilization, frame drops, CRC-errors, buffer overflows and interface utilization. These are good indicators for figuring out what could have caused message drops and therefore causing additional delays due to re-transmissions.
How a device monitoring solution helps
When you need to do these 6 steps regularly, consider deploying a more advanced type of device monitoring solution. Typically, their topology capabilities support you by automating the device discovery between 2 hosts. This is because they translate the content of MAC- and routing tables into a topology map.
Moreover, device monitoring solutions collect device and interface statistics as outlines in step 6. Some do that in a passive manner and rely on some OS service; others require the installation of an agent. Typically, the latter is the case for Linux hosts.
However, even with message based TCP session data, you have visibility on the MAC addresses of the client and the server. Be aware that, if the IP address of the client and server are not in the same subnet, the MAC-address must belong to a router (or something similar). Use this information to find out if this is indeed the expected router.
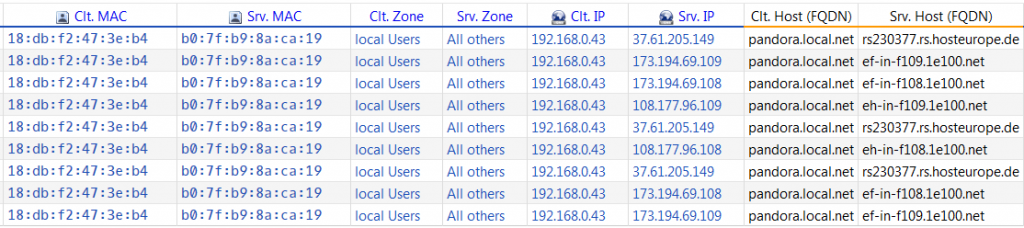
Visibility on the MAC-sddresses
A message deep-dive for one or more relationships
If the outcome of the previous, device oriented steps doesn’t show any significant issues, then the recommended next step is message deep-dives by isolating the client-side and start making PCAP-files with message traces on both, client- and server-side. Something like a triggered PCAP capability has proven to be of good value here!
Assuming these PCAP files are then analyzed with Wireshark: start with having a quick look at the “Expert information” list. There should be a few good pointers to the problematic conditions on the captured relationship data.
As you might have guessed, this ends the 4th post in which you have learned how to discover the low hanging fruit for getting healthy relationships (again). This is then used to improve the user experience in the process.
What is covered in the upcoming last episode
In the 5th (and last) post, you will learn how this TCP session data approach helps for multimedia, UDP type of applications. Reason for a seperate post is that cloud services and applications running over UDP don’t have things like TCP flags and events.
As a result, these are very fast but require error handling within the cloud service and application itself. More details on this in the upcoming blog.
Yes we have mentioned it before – all 5 posts are also available in one convenient PDF; click here to get your copy.