

 In our day-to-day practice as TCP relationship therapists for cloud services, applications and networks, more often then not, the not-so healthy starts and endings of a relationship has a significant impact on the user experience!
In our day-to-day practice as TCP relationship therapists for cloud services, applications and networks, more often then not, the not-so healthy starts and endings of a relationship has a significant impact on the user experience!
But how can you tell if relationships are healthy? And what if not-so-healthy, where to start with fixing things? To what extend is the integrity of your data impacted?
Especially in today’s end-to-end encrypted, turbo-charged, hybrid environments, it could very well be experienced as searching for some needles in a haystack!
This is the 1st post (of 5 in total) where you will learn how a basic set of TCP session data presented in an easy-to-understand format helps you to identify the low hanging fruit for performance improvements.
Each post includes practical, real-life examples based on two externally hosted e-mail services. One e-mail service is hosted by Host Europe and the other one by Google/Gmail. Moreover, references to relevant, detailed case studies are also made.
All 5 posts are also available in one convenient PDF; click here to get your copy.
Why the TCP session data approach
Reason for taking the NPM (Network Performance Monitoring), TCP session data approach is that the network is the linking pin for all cloud services, business applications and their content. Therefore TCP session data is the number-one place to look when base-lining and analyzing the healthy and the not-so healthy relationships.
While the examples are based on hosted e-mail services, this approach works for all types of cloud services as well as any type of business application; encrypted or not. You may even consider using this information as a starting point for managing the contractual aspects about performance and availability related SLO’s (i.e. Service Level Objectives); more on that later.
What is also good to know that the integrity of your services, applications and data is guaranteed because all TCP session data is collected in a 100% passive, non-intrusive manner!
It’s all about counting
As you probably know the majority of the cloud services and applications are using TCP protocols to transport data. All these protocols use TCP flags and TCP sequence numbers as a vehicle to assure reliable relationships on client- and server-side.
Counting the amount of different TCP flags for all end-user devices gives you a good understanding how your cloud services and applications are behaving! If not behaving as expected, you have a jump start on troubleshooting.
Understanding the overall health of a relationship starts with counting the amount of:
- Relationships for all end-user devices.
- TCP flags known as SYN, FIN and RST; refers to starts, endings and restarts of a relationship.
- TCP events known as DupAck (i.e. Duplicate Acknowledgement) and 0-Win (i.e. 0-Window-size); refers to the health of a relationship. Meaning the path between 2 hosts and the health of the hosts itself.
This is because, as a rule-of-thumb, healthy relationships can be identified and analyzed with the following 5 KPI’s (Key Performance Indicators) and its thresholds:
- # SYN’s – refers to relationship starts; should be twice the amount of relationships. This is because the 3-way handshake SYN | SYN-ACK | ACK (i.e. Acknowledgement) always includes 2 SYN’s. When successful a 2-channel, full-duplex relationship is ready.
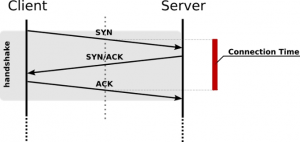
The SYN, SYN-ACK and ACK in one go indicating a healthy start of a relationship
- # FIN’s – refers to relationship endings; should roughly be twice the amount of relationships. This is because in a healthy situation each relationship ends with a FIN-ACK initiated and confirmed by both, client- and server-side. Roughly because some cloud services and applications are working with long-lasting relationships. Meaning from time-to-time, the amount of FIN’s might actually be lower than twice the amount of relationships.
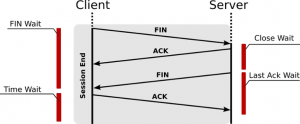
Two FIN-ACK’s in one go indicating a healthy end of a relationship
- # RST’s – refers to relationships restarts/resets; should be close to zero.
Depending on the TCP stack, it could also be an indicator on the amount of relationship-endings; similar to using a FIN-ACK. In particular Microsoft applications running over SSL are well-known for this (mis-)behavior. - # DupAck’s – refers to delayed/lost messages.
- # 0-Win’s – refers to a high system utilization; should be close to zero indicating that the involved hosts are in good shape for processing incoming messages.
Ideally the amount of RST’s, DupAck’s and 0-Win’s are all zero. This is a strong indicator for the best possible QoS (i.e. Quality-of-Service) in any given relationship!
As mentioned earlier, it is highly recommended that you base-line these 5 KPI’s. Use the results as a starting point for managing the contractual aspects about performance and availability related SLO’s. Each of these KPI’s are very helpful when answering questions like “Is it the client, the network or the server? And if a combination, to what extend each and where to start improving things?“.
This is important because more often then not, without these KPI’s and its base-lines, it takes weeks; if not months before these questions are answered.
Reading and understanding these counters
See the highlighted line in the next figure: what this line tells you is that for the given period, relationships with the 2 e-mail services were fairly healthy. The client was able to start 26 relationships in a healthy way.
This is based on the “x 1.00”-column; it shows a 1.00 indicating that the relationships where started within the first attempt of the 3-way handshake. Anything higher, like for example 1.36, indicates some relationships where started in a not-so-healthy way.
From these 26 relationships, 1 is still on-going, 24 ended in a healthy way and 1 ended in a not-so-healthy way. This is based on the different values for the columns “# Clt. FIN”, “# Srv. FIN” and “# End”. Ideally, all three should be the same.
What this figure also tells you is that both client and server are in good shape when it comes to processing incoming messages because the columns “# Clt. 0-Win” and “# Srv. 0-Win” show all zero’s.
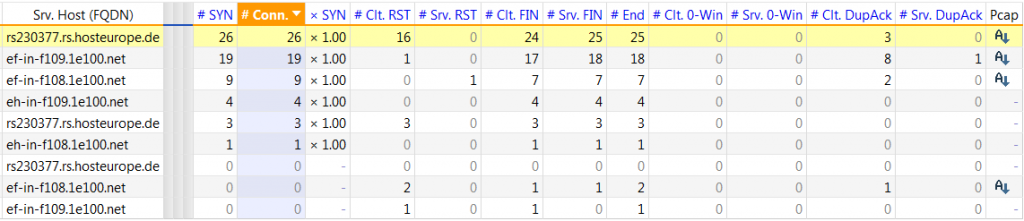
Counting TCP flags and TCP events for the 2 hosted mail services
However, the columns “# Clt. RST” and “# Clt. DupAck” tells you that there were some struggles in keeping the relationship healthy. Especially the DupAck is a good indicator for messages that are delayed or even dropped by one or more devices on the path between the client and the server.
What is covered in the next episode
This ends the 1st post in which you have learned how to identify the healthy and the not-so healthy relationships based on a few KPI’s and its thresholds.
How these not-so healthy relationships impact the user experience is covered in the upcoming posts; including one with 6 easy steps discovering the low hanging fruit for getting healthy relationships (again):
- How the not-so healthy starts of a relationship impacts the user experience; referencing a case study on a Citrix/SAP application chain (part 2)
- How the not-so healthy endings of a relationship impacts the user experience; referencing a case study on the Dutch Dedicon app called “Daisylezer” (part 3)
- How to get healthy relationships (again) with 6 easy steps (part 4)
- How this works for multimedia, UDP type of applications (part 5)
As mentioned earlier, all 5 posts are also available in one convenient PDF; click here to get your copy.