

The user experience of applications and cloud services depends on the overall, end-to-end performance and availability. This includes assuring the shortest problem resolution time if things are not behaving as expected.
In this blog 3 practical, actionable steps to help you make it run like clockwork in no time!

Step 1: Get the basics right
Getting the basics right is about finding the low-hanging fruit within the devices of the technical infrastructure:
- How the real infrastructure topology looks like
- Workload and errors of devices like routers, switches and bare metal servers
- Settings of network connections; typically speed and FDX/HDX related
- Workload, performance and error of software services; including IaaS and PaaS like AWS and Azure
To reveal this low hanging fruit, start with collecting statistics via SNMP, WMI and a few API calls.
Typically, SNMP is used for network and Linux devices while WMI is used for Windows systems. Combined this gives you visibility on the workload and performance @ device-OS level, what software services are running on the servers and how all this is connected (i.e. the real application and infrastructure topology).
The API calls are used on the IaaS and PaaS services as available from different vendors. Depending on your subscription this is used to collect resource usage of the services and the response times of the application calls.
Once the individual technologies of your infrastructure are behaving as expected it is time to move on with the next step.
Step 2: User plane, end-to-end visibility
This step is about visibility on the end-to-end behavior of applications as experienced by real users. This end-to-end, user plane is important because typically, while everything seems to be in the green at device level, it can very well be that the chain of devices and applications are still not behaving as expected.
To identify (and fix!) such issues requires a different data set like for example:
- End-user response times
- Response times and data transfer times for each of the application components
- Network/TCP visibility aspects like re-transmissions and delays across all security layers
The recommended data source for this is the network because whatever the amount of horse power is on both ends, the proof is in the wire!
This is because the client side and the wire gives you visibility on the real connections between their respective IP end-nodes. In addition, both will reveal to what extend these connections are healthy (or not). If not, which connections, users and IP end-nodes are suffering most, why that is and where to start with problem-solving.
Once these network/TCP connections are healthy again, it is time to move on with an application deep-dive figuring out the root-cause and its server dependencies before moving on to the next step.
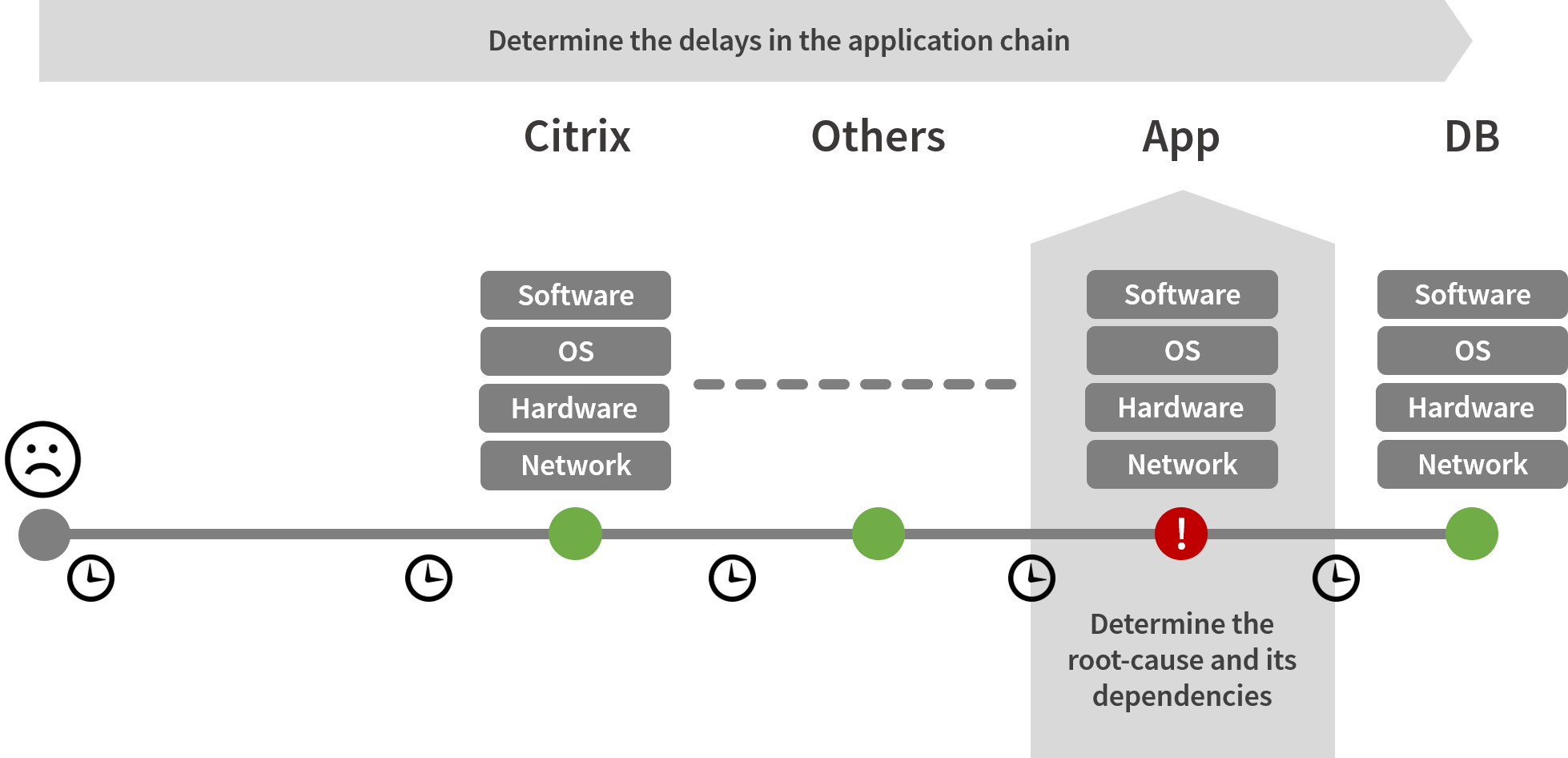
Step 3: Application deep-dives
We now have reached a point where application packets and underlying networks are behaving as expected. However, users may still experience availability and performance issues because certain applications tend to hide troublesome conditions. This particularly true for web applications that rely on a significant amount of public Java libraries and 3rd party content.
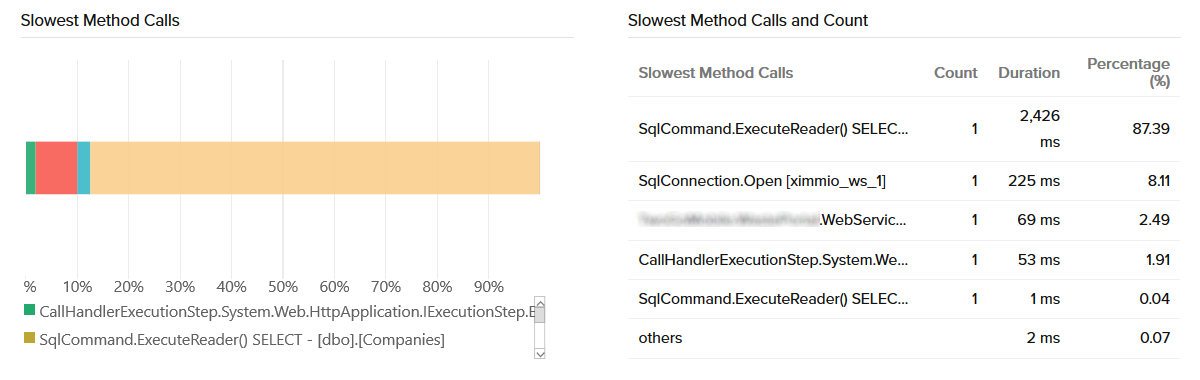
To reveal these troublesome conditions we start with measuring the user experience and code execution times that include (but is not limited!) the following details:
- The outcome of user clicks as executed by the user device and the application chain.
- Real-time, code-level visibility by user for each component in the application chain.
- Browser render times and error conditions by region, by telco provider, by browser and by device type.
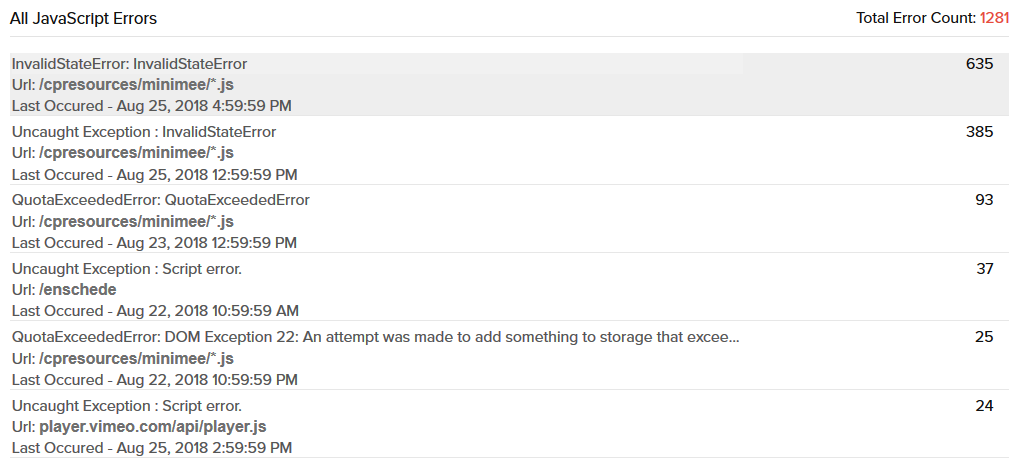
To reveal the data around these hidden, troublesome conditions agents are installed on the user device and application servers. These agents track user clicks and trace them across the application chain.
The result is detailed visibility on what users where clicking on within the front-end of each web and non-web application; potentially including the application code that was executed and what database queries where involved.
Conclusion
Depending on the issues users are experiencing, finding the root-cause is not an easy task: is it the client, the network, the server or the application? And if a combination of these, to which extend each?
In today’s cloud and data driven application landscape, answering and solving things manually with processes and procedures is experienced as a mission-impossible by the DevOps and ITOM teams.
This 3-step approach helps you by breaking things down to small, feasible parts. Each of these steps can be executed independently from the other. However, in terms of cause-and-effect, we strongly recommend starting with step 1; potentially running in parallel with step2.